
Toba
Meet Toba the cat, the latest security shield model, equipped with 24/7 surveillance mode and an aggressive defense mechanism when unauthorized movement is detected. 🚨😼
Any attempt to relocate this elite guardian from the server rack results in immediate resistance, accompanied by sharp glares and indignant meows. 🛑🐾
Plan to Host Mastodon on 4 × Raspberry Pis
In my current homelab project, I am building a bare-metal Kubernetes cluster to host ~10–50 containers per node. What app will run there? Well, I’ll figure that out along the way, but I’m considering hosting Mastodon. (For those who don’t know, Mastodon is a decentralized microblogging platform.)
No Hypervisors for This Project 🚫
As you might know from my previous posts, I have 4× Raspberry Pi 5 boards. Each features a 64-bit quad-core ARM Cortex-A76 processor running at 2.4GHz with 8 GB RAM. In my setup, 3 Raspberry Pis act as worker nodes, while 1 serves as the control plane (in the future, I’ll increase it to 3 to meet RAFT consensus, but for now, this setup is fine).
Kubernetes pods will run directly on the host OS. The OS is Raspberry Pi OS (64-bit), booted over the LAN network. If you’re interested, you can read more in this post about setting up PXE boot.
Even though Raspberry Pi 5 delivers a 2–3× increase in CPU performance compared to Raspberry Pi 4, I’m avoiding virtualization solutions like VMware and Proxmox (I like Proxmox, but not for this setup) because they introduce unnecessary overhead.
➕ One day, I’m thinking about building a voice assistant (currently, I have a Siri HomePod but want to make it smarter) that interacts with LLMs and controls physical devices like smart sockets, lights, or energy monitoring systems. For that, I need access to GPIO pins (direct hardware interaction). Virtualization makes passing through “exotic” hardware problematic, so running on bare metal is the better choice.
What is for dinner? 💭
In today’s post, I am going to shed a light on the issue I faced with PXE boot on NFS and containderd’s component snapshotter that is not compatible with NFS. But how I come to that conclusion? let’s check it out.
dmesg, linux kernel dump tool spaws this log ⬇️
[Thu Feb 6 09:20:56 2025] overlayfs: upper fs does not support tmpfile.
[Thu Feb 6 09:20:56 2025] overlayfs: upper fs does not support RENAME_WHITEOUT.
[Thu Feb 6 09:20:56 2025] overlayfs: failed to set xattr on upper
[Thu Feb 6 09:20:56 2025] overlayfs: ...falling back to redirect_dir=nofollow.
[Thu Feb 6 09:20:56 2025] overlayfs: ...falling back to uuid=null.
[Thu Feb 6 09:20:56 2025] overlayfs: upper fs missing required feature
and kubectl describe pod shows this error, but they are both about that same matter.
kubectl describe pod -l app=nginx --namespace default --kubeconfig /opt/hl-control-node/_tmp/kubeconfigs/admin.kubeconfig
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedCreatePodSandBox 13m (x19065 over 2d23h) kubelet (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to start sandbox "1323c487a948330ef32a782dc48095e74998758163f49401ce91cd649013d8ec": failed to create containerd task: failed to create shim task: failed to mount rootfs component: invalid argument
Warning FailedCreatePodSandBox 5m29s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to start s
overlayfs is one of the file systems that used by snapshotter. upper fs is literally my “upper FS” in my case it is NFS, since my Entire Root Filesystem (/) is on NFS.
df -h
Filesystem Size Used Avail Use% Mounted on
udev 3.8G 0 3.8G 0% /dev
tmpfs 806M 5.3M 801M 1% /run
192.168.101.253:/volume1/RPi5-PXE/node4/rootfs 885G 148G 737G 17% /
tmpfs 4.0G 0 4.0G 0% /dev/shm
tmpfs 5.0M 48K 5.0M 1% /run/lock
192.168.101.253:/volume1/RPi5-PXE/node4 885G 148G 737G 17% /boot
tmpfs 806M 0 806M 0% /run/user/1000
all this means that network file system doesn’t have required features like: tmtfile; RENAME_WHITEOUT; xattr.
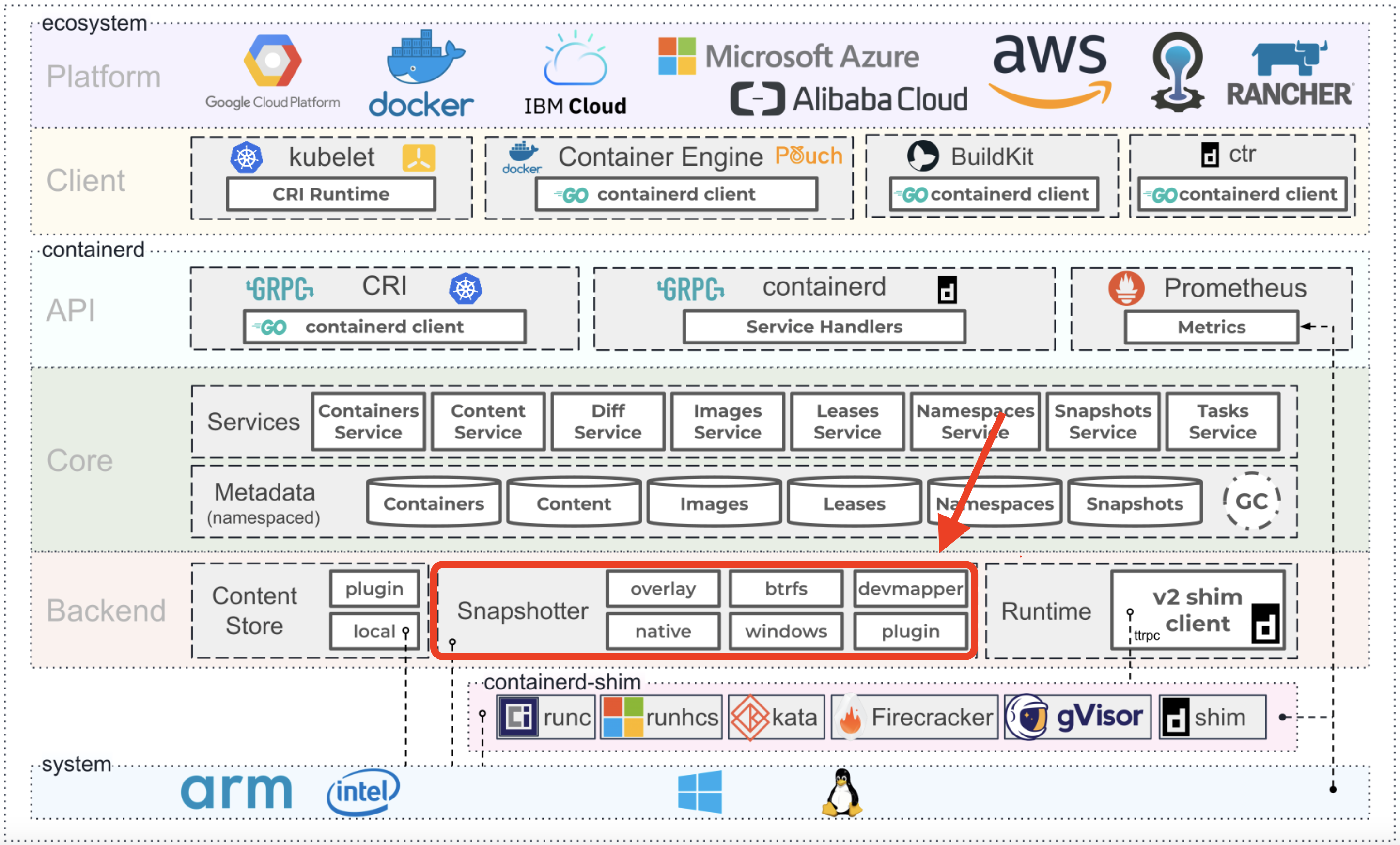
Image taken from official source https://containerd.io
my first thought was to switch overlayfs into btrsfs or devmapper storage drivers, but is is “bargain one trouble for another” rather then help. all these storage drivers works by allocating block storage.
here is my illustration how block storage works:
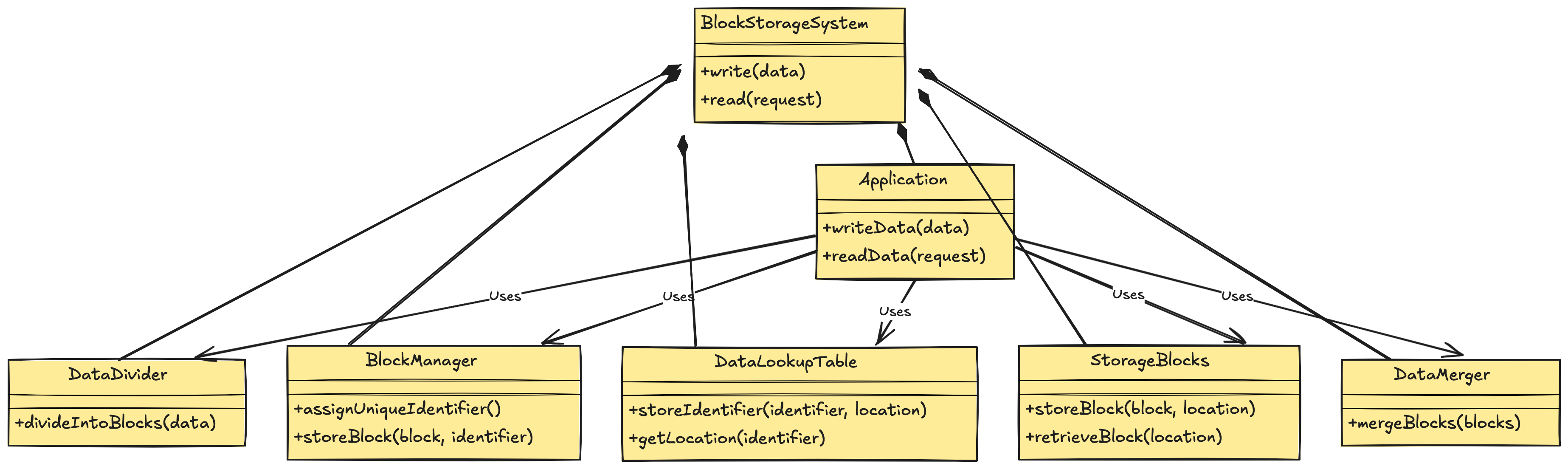
in comparision to network file storage, it has a logic on top of file storage that is responsible for assign unique identifiers to files which are stored in the data lookup table. read operations are obviously much more faster then in a unsturctured storage like nfs.
and it means that for making k8s work in the current setup i need to “transform” those directories that kuberenets need into block storage type. and solution for that is iSCSI (/aɪˈskʌzi/ eye-SKUZ-ee). boom.
iSCSIfication
iSCSI (Internet Small Computer System Interface)
Wiki: iSCSI provides block-level access to storage devices by carrying SCSI commands over a TCP/IP network.
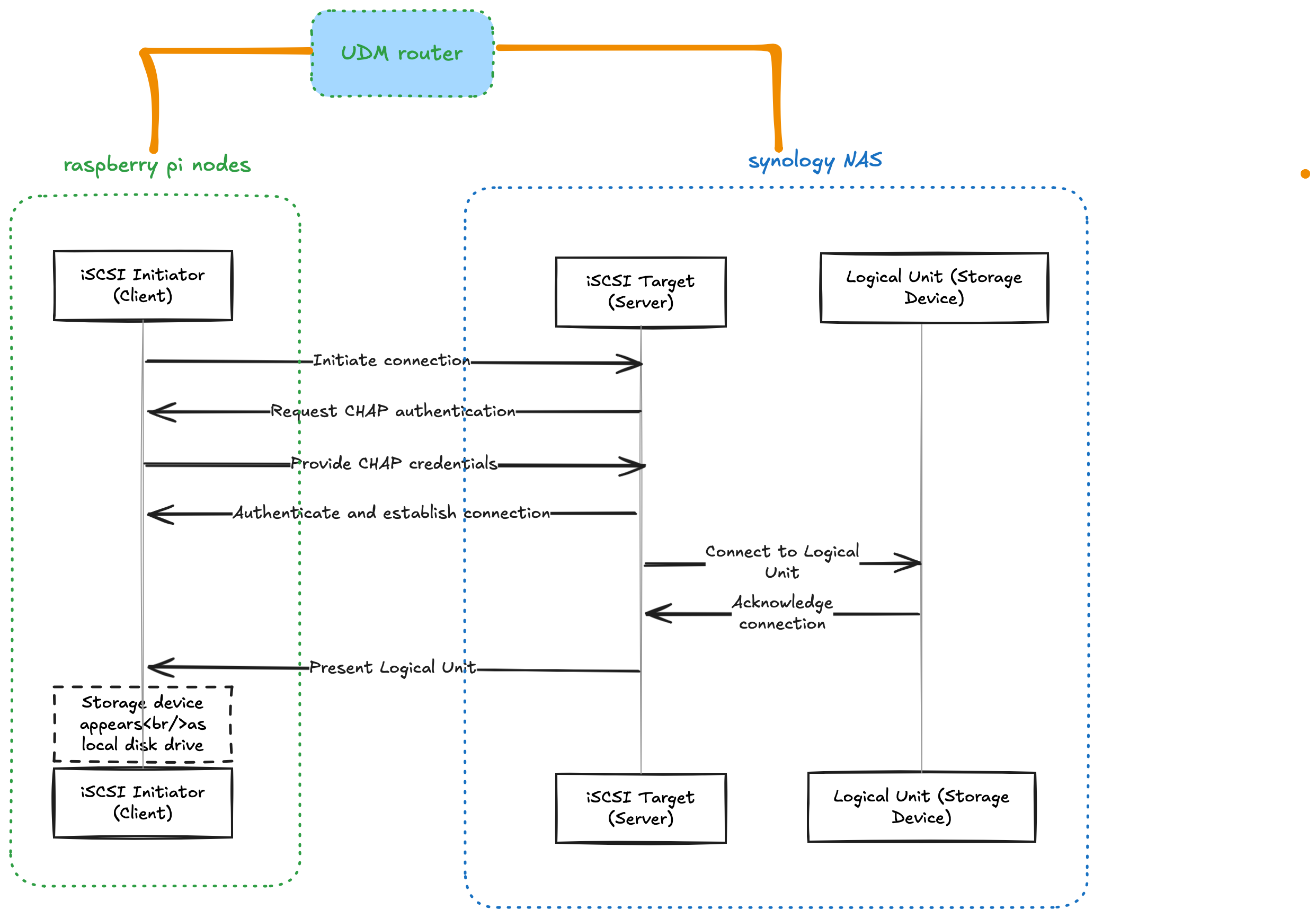
iSCSI allows remote data sharing (same as nfs) but at the block level. It enables data exchange between multiple client machines and a block storage device (or block server), which is accessed similarly to a local disk drive.
here is illustration how it works in with my homelab devices
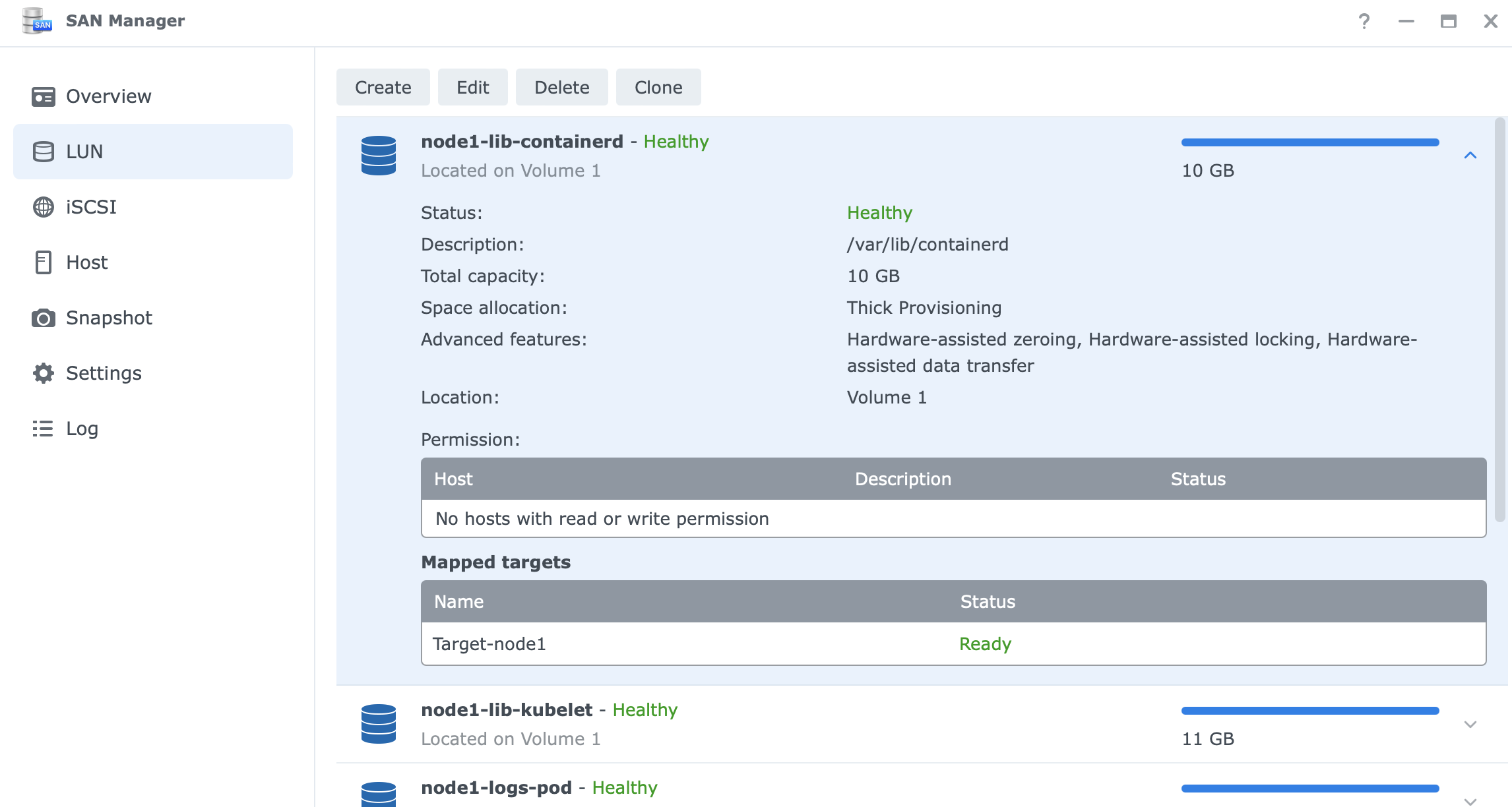
Setting up iSCSI on Synology NAS
- create an iSCSI Targets for each cluster node.
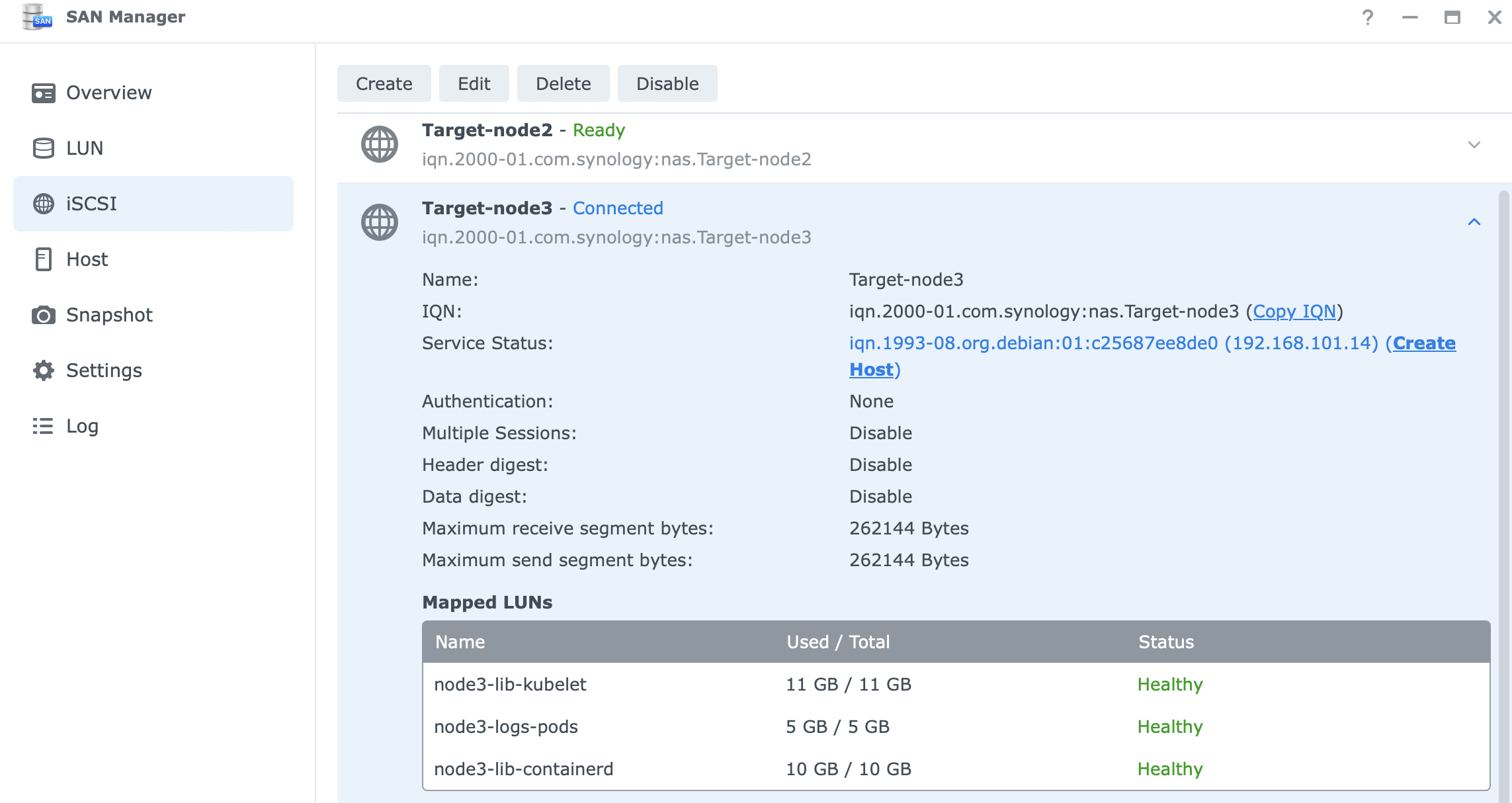
- define logical unit numbers (LUN) for:
/var/lib/containerd(stores container images and metadata)/var/lib/kubelet(kubernetes node-specific data)/var/logs/pods(stores logs from running containers)
Configuring iSCSI Initiator on Raspberry PI nodes
- install the iscsi client:
sudo apt install -y open-iscsi sudo systemctl enable --now open-iscsi - discover the iscsi targets:
iscsiadm -m discovery -t st -p 192.168.101.253 - login to the iscsi target:
sudo iscsiadm -m node --targetname "iqn.2000-01.com.synology:nas.Target-node3" --portal "192.168.101.253:3260" --login
3.1. enable iSCSI auto-login, to restore session after reboot
sudo iscsiadm -m node --targetname "iqn.2000-01.com.synology:nas.Target-node3" --portal "192.168.101.253:3260" --op update -n node.startup -v automatic
- format the block devices as
ext4:sudo mkfs.ext4 -L kubelet /dev/sda sudo mkfs.ext4 -L logs /dev/sdb sudo mkfs.ext4 -L containerd /dev/sdcyuklia@node3:~ $ sudo blkid /dev/sda /dev/sda: LABEL="kubelet" UUID="317346de-f632-4f5d-9ec0-90770f56938d" BLOCK_SIZE="4096" TYPE="ext4" yuklia@node3:~ $ sudo blkid /dev/sdb /dev/sdb: LABEL="logs" UUID="d35111a5-f56a-4bde-a731-87e630fa0aed" BLOCK_SIZE="4096" TYPE="ext4" yuklia@node3:~ $ sudo blkid /dev/sdc /dev/sdc: LABEL="containerd" UUID="8c83f195-eb3e-4226-914d-98837e3ddcca" BLOCK_SIZE="4096" TYPE="ext4"
4.1 update fstab to persist mount targets after reboot
cat /etc/fstab
proc /proc proc defaults 0 0
192.168.101.253:/volume1/RPi5-PXE/node4 /boot nfs defaults,vers=3,proto=tcp 0 0
UUID=317346de-f632-4f5d-9ec0-90770f56938d /var/lib/kubelet ext4 defaults,_netdev 0 0
UUID=d35111a5-f56a-4bde-a731-87e630fa0aed /var/logs/pods ext4 defaults,_netdev 0 0
UUID=8c83f195-eb3e-4226-914d-98837e3ddcca /var/lib/containerd ext4 defaults,_netdev 0 0
-
mount the block devices:
sudo mount /dev/sda /var/lib/kubelet sudo mount /dev/sdb /var/logs/pods sudo mount /dev/sdc /var/lib/containerd -
update
/etc/fstabto persist mounts:UUID=317346de-f632-4f5d-9ec0-90770f56938d /var/lib/kubelet ext4 defaults,_netdev 0 0 UUID=d35111a5-f56a-4bde-a731-87e630fa0aed /var/logs/pods ext4 defaults,_netdev 0 0 UUID=8c83f195-eb3e-4226-914d-98837e3ddcca /var/lib/containerd ext4 defaults,_netdev 0 0 -
job done
yuklia@node3:~ $ df -h Filesystem Size Used Avail Use% Mounted on udev 3.8G 0 3.8G 0% /dev tmpfs 806M 5.4M 800M 1% /run 192.168.101.253:/volume1/RPi5-PXE/node4/rootfs 885G 227G 658G 26% / tmpfs 4.0G 0 4.0G 0% /dev/shm tmpfs 5.0M 48K 5.0M 1% /run/lock /dev/sdb 4.9G 24K 4.6G 1% /var/logs/pods /dev/sda 11G 124K 11G 1% /var/lib/kubelet /dev/sdc 9.8G 270M 9.0G 3% /var/lib/containerd 192.168.101.253:/volume1/RPi5-PXE/node4 885G 227G 658G 26% /boot tmpfs 806M 0 806M 0% /run/user/1000
Smoke test ?
kubectl get pod -l app=nginx
oh, no CrashLoopBackOff
...
Reason: CrashLoopBackOff
Last State: Terminated
Reason: StartError
Message: failed to create containerd task: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error setting cgroup config for procHooks process: unified resource "memory.oom.group" can't be set: controller "memory" not available
Root Cause: memory.oom.group Can’t Be Set This means
the container runtime (containerd + runc) is trying to set memory cgroup configurations, but the memory cgroup controller is missing or not enabled on your system.
updating kernel boot parameters with systemd.unified_cgroup_hierarchy=1 cgroup_enable=memory helped.
sudo cat /boot/cmdline.txt
dwcotg.lpm_enable=0 console=serial0,115200 console=tty1 elevator=deadline rootwait rw root=/dev/nfs nfsroot=192.168.101.253:/volume1/RPi5-PXE/node4/rootfs,v3,tcp ip=dhcp cgroup_enable=memory cgroup_memory=1 systemd.unified_cgroup_hierarchy=1
Smoke test-test 🧪
check that all nodes up & running
kubectl get nodes --kubeconfig /opt/hl-control-node/_tmp/kubeconfigs/admin.kubeconfig
NAME STATUS ROLES AGE VERSION
node1 Ready <none> 37d v1.31.2
node2 Ready <none> 37d v1.31.2
node3 Ready <none> 37d v1.31.2
check that nginx pod up & running
kubectl get pod -l app=nginx --namespace default --kubeconfig /opt/hl-control-node/_tmp/kubeconfigs/admin.kubeconfig
NAME READY STATUS RESTARTS AGE
nginx-54f87867d6-9tbgl 1/1 Running 0 3h13m
Final Thoughts
I started with PXE boot and NFS, thinking it would be a clean and efficient solution. However, I quickly encountered limitations due to OverlayFS incompatibility in containerd. After troubleshooting, I realized that NFS wasn’t sufficient and decided to pivot to iSCSI block storage.
Setting up iSCSI on my Synology NAS and configuring the initiators on the Raspberry Pi nodes required some effort. Once completed, it resolved the persistent storage issue. Of course, Kubernetes wouldn’t let me off that easy. I hit another roadblock with memory cgroup issues, which I fixed by tweaking kernel boot parameters.
After all the adjustments and smoke tests, the cluster is now running smoothly. I can finally deploy workloads without storage headaches. Next step? Automating iSCSI provisioning with OpenTofu (Terraform) to make scaling effortless. Stay tuned for that adventure! 🚀